
Nosql, Python and password

The latest news around the “so-called” compromise of Google accounts calls for some modernization in research and development structured around two axes:
- Complexity analysis of a set of passwords accumulated for more than 10 years,
- The aggregation of passwords in order to build a knowledge base built on the statistical use of passwords that are actually used.
Our requirements consisted of the following primitives:
- Accepting a file as input containing a set of passwords to be analysed, structured in the form of one password per line encoded in latin-1 or utf-8,
- Implementing clean-up mechanisms of the analysed entries to normalize penetration test dictionaries,
- Integrating the extraction of a “copy” of the original file on the basis of their occurrences,
- Creating an analysis of the complexity of different “unit” passwords encountered in the analyzed files: length, set of characters used, and number of occurrences,
During the PassMAID development phase, we relied on publicly available lists of passwords (more than 100 million entries).
The “challenge” of the PassMaid project is not induced by password analysis operations completed in Python, but it lies at the storage level of the various entries for the analysis operations and also in building the knowledge base. The large volume of data to process and store pointed us towards the use of a NoSQL database.
After some evaluations, we chose the Redis database under the BSD license. This technology is particularly suitable for the storage of a large number of low complexity entries, especially when the principle of durability is not required: in fact, Redis maintains the set of stored data in RAM (150 MB per million stored entries). This feature allows for not introducing a noticeable difference between reading and writing operations while providing good performance for analysis operations.
The file to be analyzed is read line-by-line and clean-up operations are performed on each of the recovered entries, so as to preserve only the data that is considered valid. If an entry is considered to be invalid because it was excluded by one of the various active filters, it is ignored.
To ensure the consistency of data throughout the analysis, each entry is converted to unicode and then stored in the database using UTF-8 coding, because Redis does not accept the storage of character strings in unicode format.
Password backup is carried out using two “sorted set” objects: the first for the storage of temporary data relative to the analyzed file, and the second for management of the knowledge base.
This data type represents the “password / number of occurrence” association. In addition, the primitives associated with this type of data allow us to perform password classification operations with a low processing cost. Thus, a single “ZINCRBY” instruction is necessary to verify the presence of a password in the database and add it if necessary.
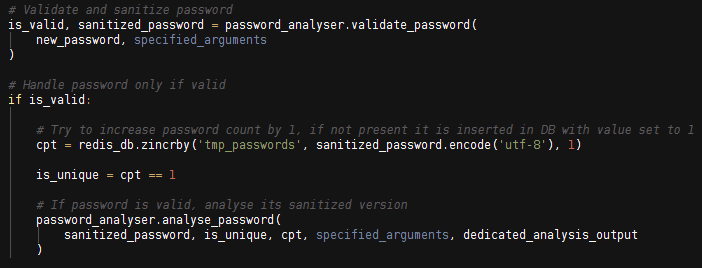
To date, the storage capacity limit of the knowledge base corresponds to the maximum number of entries that can be inserted into a “sorted set” object: 2^32 – 1 elements, or more than 4 billion unique entries (4,294,967,295). This capability can be extended by using a dynamic number of “sorted sets.”
To increase the file analysis speed submitted in entry, Redis offers the possibility of using a “pipeline” to overcome the RTT (Round Trip Time) between two network requests: the pipeline allows multiple queries to be sent to the database without having to wait for responses, and then reads all the responses.
Another approach consists of distributing the analysis execution between several processes through the use of the Python “multiprocessing” module.
In the case of a “local” execution where the same machine performs the analysis and storage of data, using several process has proven to be more effective than using a pipeline. This solution offers us a gain of more than three minutes on the analysis of a “RockYou” type of file.
The global statistics obtained are as follows:
[+] Global statistics ********************** [-] Total entries: 14,344,390 [-] Analyzed password entries: 14,331,467 [-] Excluded password entries: 12,923 [-] Unique passwords: 14,330,630
The analyzed “RockYou” file contained 14,344,390 entries, of which 12,923 were excluded by the various filters enabled during the execution (default configuration of the script). Among the non-excluded entries, 14,330,630 were unique entries. Redundant entries are due to backslash clean-up operations.
The distribution of unique entries in terms of length is as follows:
[+] Password lengths (for unique entries)
*****************************************
[-] 1: 46 password(s) [ 00.0003 % ]
[-] 2: 339 password(s) [ 00.0024 % ]
[-] 3: 2,472 password(s) [ 00.0172 % ]
[-] 4: 18,099 password(s) [ 00.1263 % ]
[-] 5: 259,533 password(s) [ 01.8110 % ]
[-] 6: 1,948,796 password(s) [ 13.5988 % ]
[-] 7: 2,507,212 password(s) [ 17.4955 % ]
[-] 8: 2,966,487 password(s) [ 20.7003 % ]
[-] 9: 2,190,663 password(s) [ 15.2866 % ]
[-] 10: 2,012,917 password(s) [ 14.0463 % ]
...
...
We found that the vast majority of passwords (approximately 80%) have a length between 6 and 10 characters.
The following statistics highlight the composition of various identified passwords and the most frequently encountered entries during the analysis.
[*] Top 10 passwords
---------------------------------------------------
[-] \ 11 appearance(s)
[-] asdfghjkl;' 05 appearance(s)
[-] 1234567890-=\ 04 appearance(s)
[-] ojkiyd0y' 04 appearance(s)
[-] iydotgfHdF'j 04 appearance(s)
[-] J'ADENKHYA 04 appearance(s)
[-] iyd0y' 04 appearance(s)
[-] iydgmv0y' 04 appearance(s)
[-] ohv's,k 04 appearance(s)
[-] zhane' 03 appearance(s)
[*] Charset analysis (for unique entries)
------------------------------------------
[-] lowercase / numbers:
6,082,774 password(s) [ 42.4460 % ]
[-] lowercase:
3,771,685 password(s) [ 26.3190 % ]
[-] numbers:
2,347,074 password(s) [ 16.3780 % ]
[-] lowercase / ascii_special / numbers:
415,202 password(s) [ 02.8973 % ]
...
...
The analysis of these results indicates that 40% of the analyzed passwords consisted of lowercase letters and numbers, 26% had only lowercase letters, and 16% consisted of only numbers.
Our PassMAID tool is available free by simple request at tools@talsion.com, for anyone with a legitimate reason to use it and hold it in compliance with Article 323-3-1 of the French criminal code.


